合并段
通过每秒自动刷新创建新的段,用不了多久段的数量就爆炸了。有太多的段是一个问题。每个段消费文件句柄,内存,cpu资源。更重要的是,每次搜索请求都需要依次检查每个段。段越多,查询越慢。
ES通过后台合并段解决这个问题。小段被合并成大段,再合并成更大的段。
这是旧的文档从文件系统删除的时候。旧的段不会再复制到更大的新段中。
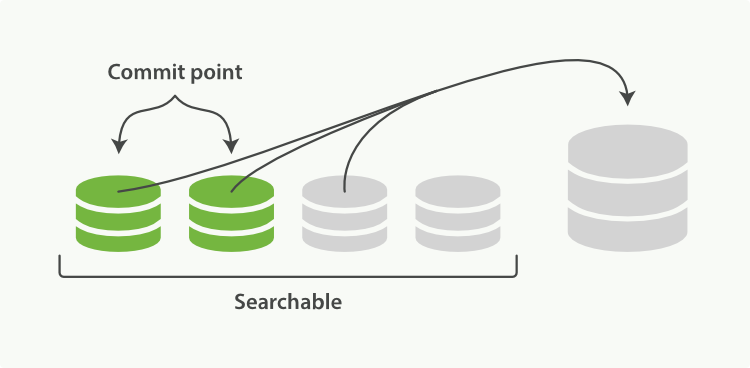
这个过程你不必做什么。当你在索引和搜索时ES会自动处理。这个过程如图:两个提交的段和一个未提交的段合并为了一个更大的段所示:
- 索引过程中,refresh会创建新的段,并打开它。
合并过程会在后台选择一些小的段合并成大的段,这个过程不会中断索引和搜索。
图1:两个提交的段和一个未提交的段合并为了一个更大的段
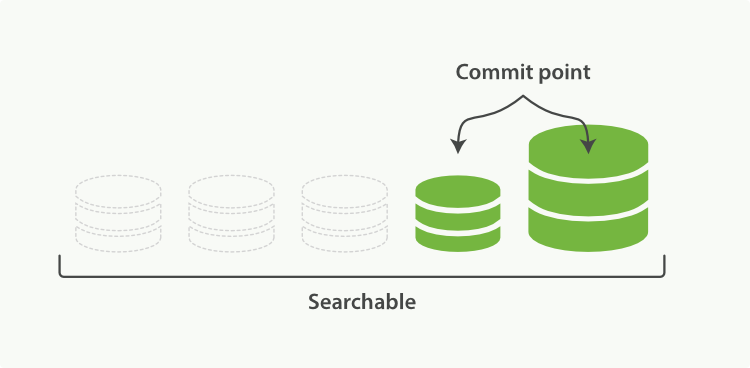
下图描述了合并后的操作:
- 新的段flush到了硬盘。
- 新的提交点写入新的段,排除旧的段。
- 新的段打开供搜索。
旧的段被删除。
图2:段合并完后,旧的段被删除
合并大的段会消耗很多IO和CPU,如果不检查会影响到搜素性能。默认情况下,ES会限制合并过程,这样搜索就可以有足够的资源进行。
optimize API
optimize API最好描述为强制合并段API。它强制分片合并段以达到指定max_num_segments参数。这是为了减少段的数量(通常为1)达到提高搜索性能的目的。
警告
不要在动态的索引(正在活跃更新)上使用
optimize API。后台的合并处理已经做的很好了,优化命令会阻碍它的工作。不要干涉!
在特定的环境下,optimize API是有用的。典型的场景是记录日志,这中情况下日志是按照每天,周,月存入索引。旧的索引一般是只可读的,它们是不可能修改的。
这种情况下,把每个索引的段降至1是有效的。搜索过程就会用到更少的资源,性能更好:
POST /logstash-2014-10/_optimize?max_num_segments=1 <1>
- <1> 把索引中的每个分片都合并成一个段